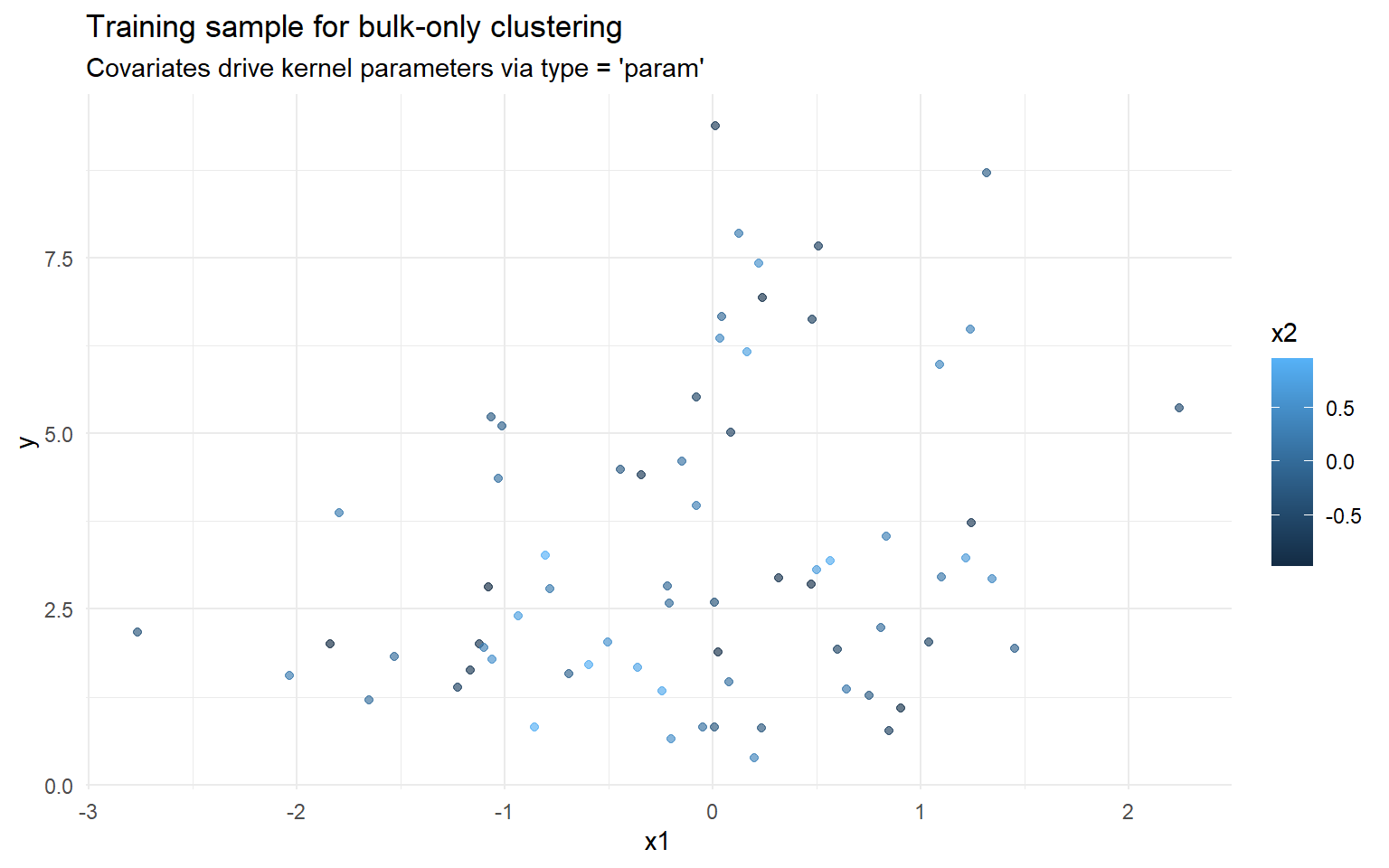
ex16. Clustering with Regular Kernel (Parameter Links + Covariates)
Website workflow note. This page reflects the current exported clustering API built around dpmix.cluster(), predict(), summary(), and plot(). Last updated: 2026-03-19.
For the package-level theory and longer narrative, see the manuscript and the clustering discussion in the main package articles.
Clustering with a Regular Kernel and Covariate-Dependent Parameter Links
Purpose: Fit a bulk-only clustering model in which covariates affect component-specific kernel parameters (type = "param"), while mixture weights remain global.
What you’ll learn
How dpmix.cluster() differs from outcome modeling: the goal is partitioning / labeling, not density prediction alone.
What type = "param" means: covariates shift within-cluster kernel parameters while mixture weights remain global.
How to use predict(..., type = "label" | "psm") plus summary()/plot() for cluster interpretation and stability.
When to use this template
You want covariates to explain how clusters behave internally (component parameters), not just reweight cluster membership.
You need train/test labeling where new points map back to a representative training partition.
Next steps
Compare against the type = "weights" clustering mode (ex15) when covariates should drive cluster membership rather than component parameters.
Here the formula still defines the full covariate structure, but type = "param" means the model uses those predictors to shift component-specific kernel parameters rather than the cluster weights. This matches the parameter-link clustering formulation described in the manuscript.
Training Labels and Cluster Summaries
Code
cluster_psm_param <-predict(fit_cluster_param, type ="psm")cluster_train_param <-predict(fit_cluster_param, type ="label", return_scores =TRUE)fit_summary_param <-summary( fit_cluster_param,vars =c("y", "x1", "x2"),top_n =5)train_sizes_tbl <-tibble(cluster =paste0("C", names(fit_summary_param$cluster_sizes)),n =as.integer(fit_summary_param$cluster_sizes))train_sizes_tbl
# A tibble: 1 × 2
cluster n
<chr> <int>
1 C1 70
Code
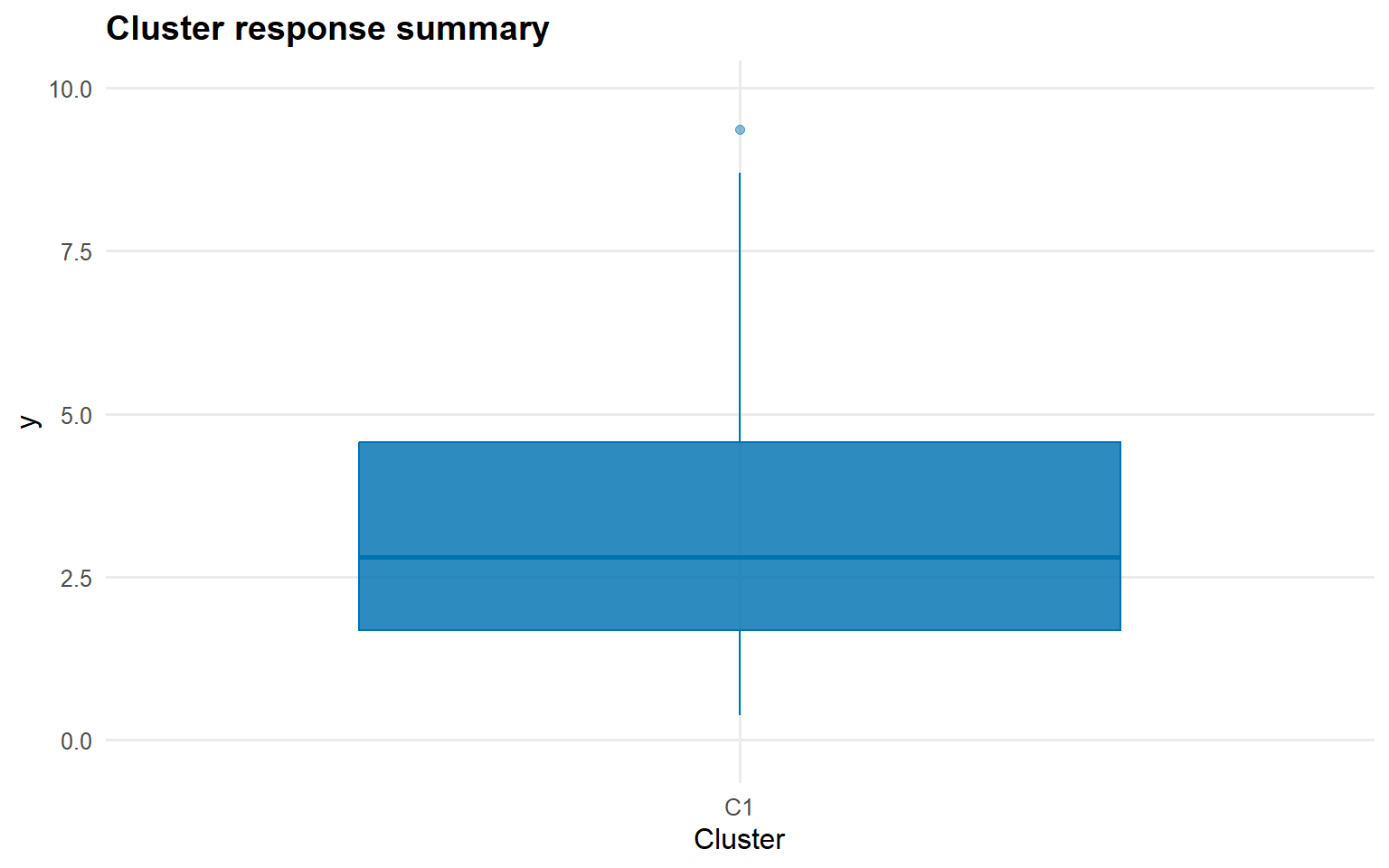
plot(fit_cluster_param, which ="summary", top_n =5)
Code
plot(cluster_train_param, type ="sizes", top_n =5)
Code
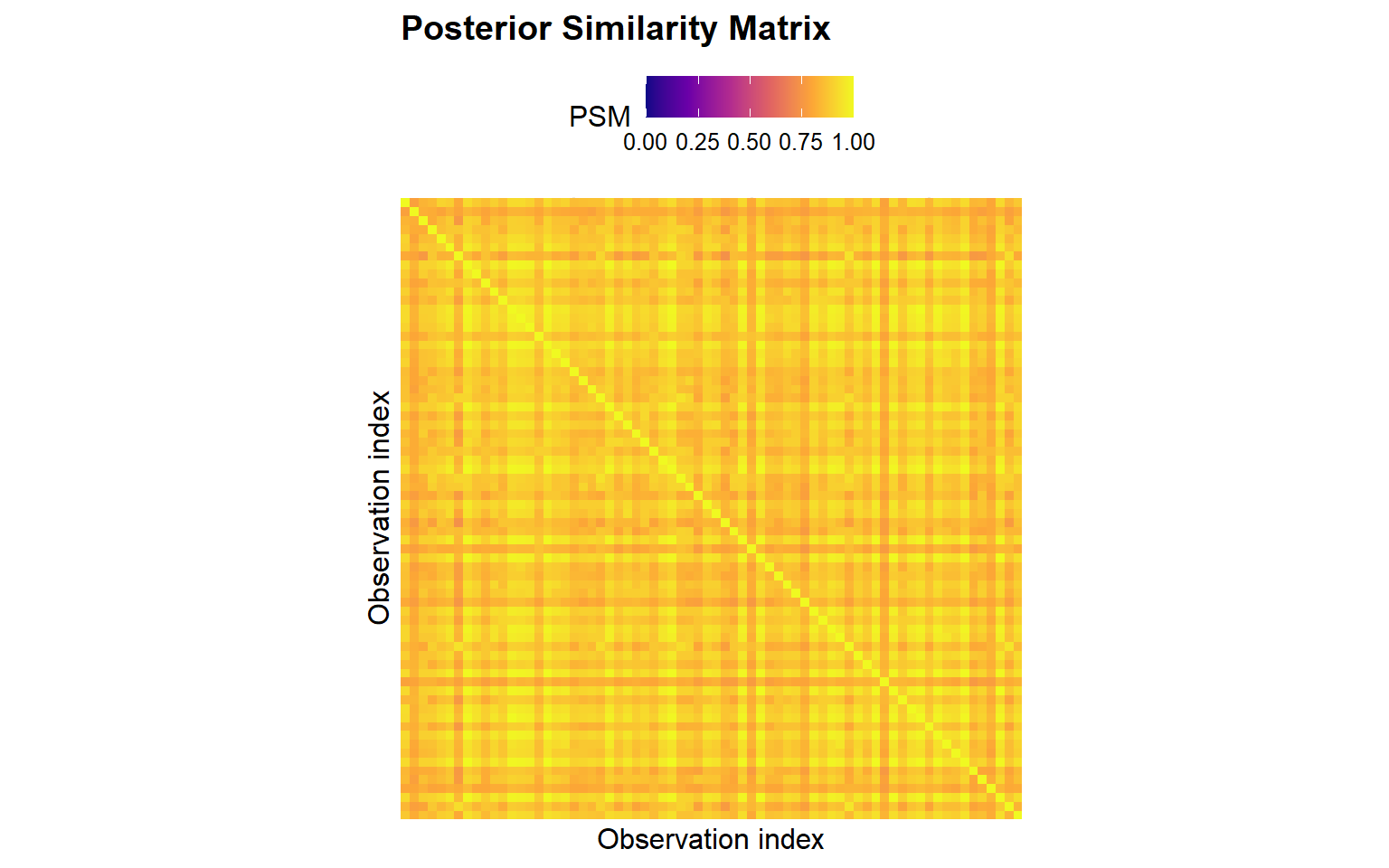
plot(cluster_psm_param)
The fit-level and label-level plotting methods expose the same representative partition from different angles: size summaries, response summaries, and the full posterior similarity matrix.
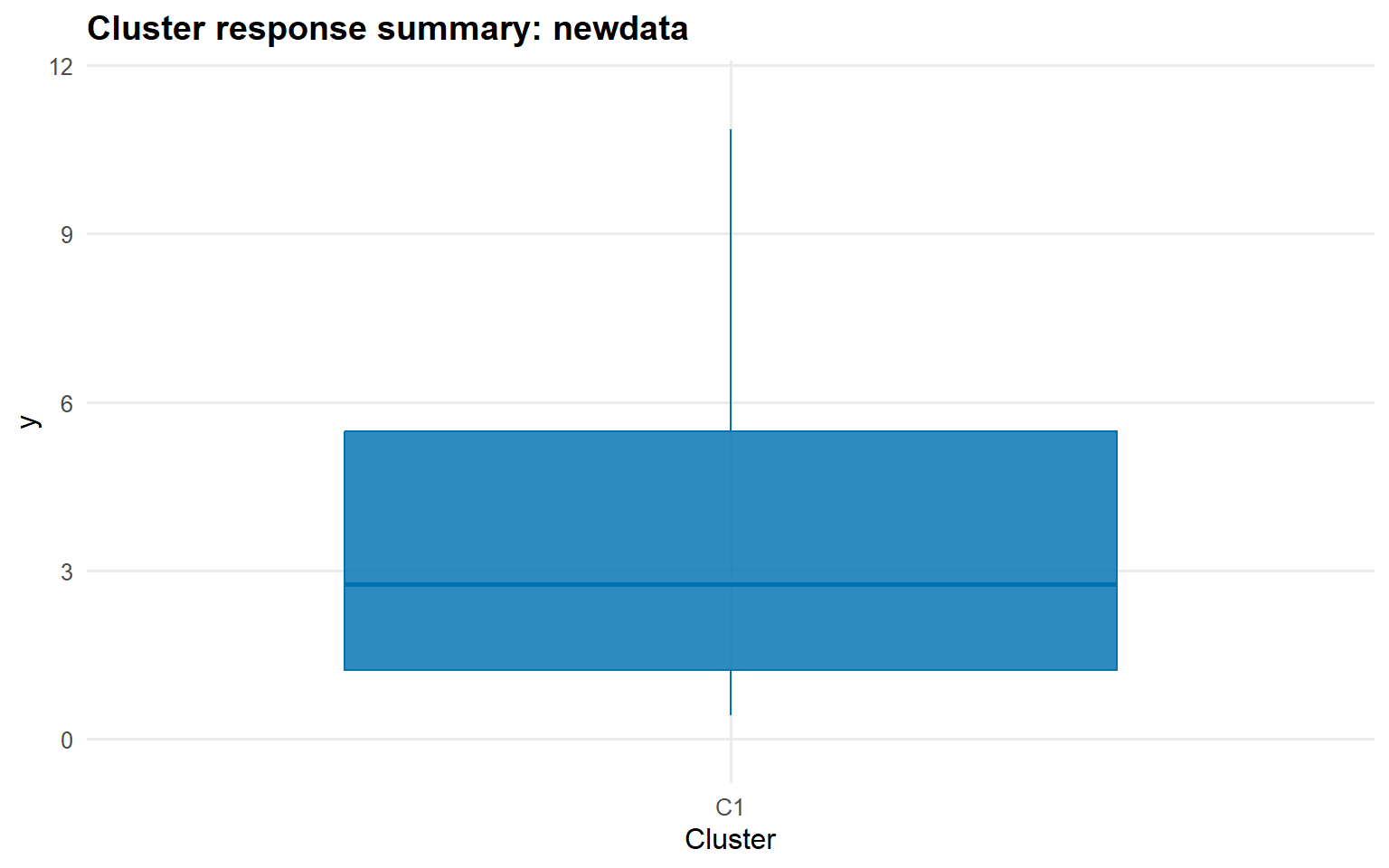
plot(cluster_new_param, type ="summary", top_n =5)
Code
plot(cluster_new_param, type ="certainty")
For newdata, the labels are returned in the space of the representative training clusters, which makes train/test comparison straightforward without exposing component-label switching from the sampler.
Takeaways
dpmix.cluster() is the current wrapper for bulk-only clustering.
type = "param" is appropriate when covariates should alter within-cluster regression/parameter structure while keeping global mixture weights.
The same three-step workflow applies as in the spliced example: fit, predict(..., type = "psm" | "label"), then summary() and plot().
This closes the examples sequence with the two main clustering modes now exposed by the package website.