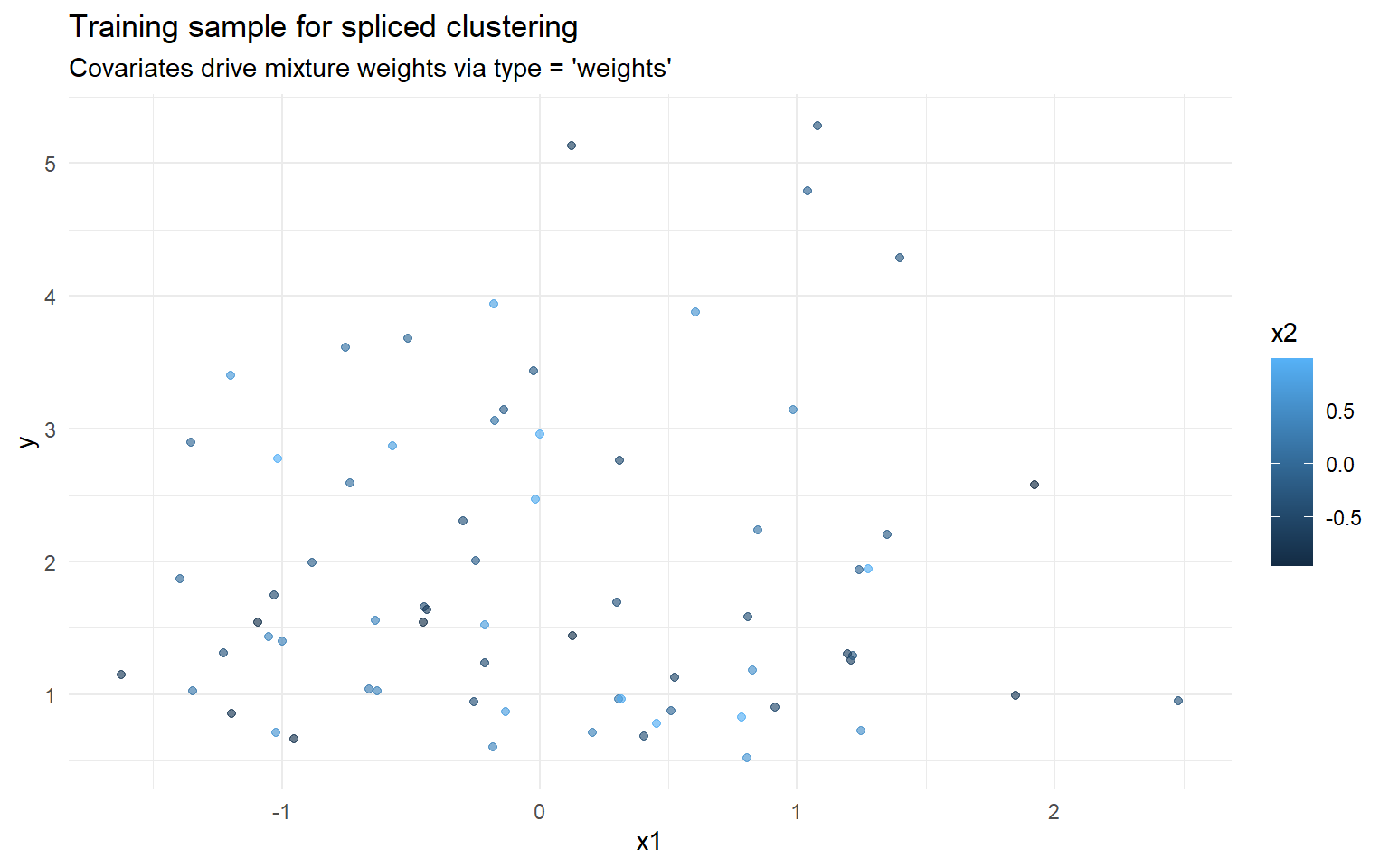
ex15. Clustering with GPD Tail (Weights + Covariates)
Website workflow note. This page reflects the current exported clustering API built around dpmgpd.cluster(), predict(), summary(), and plot(). Last updated: 2026-03-19.
For the package-level theory and longer narrative, see the manuscript and the clustering discussion in the main package articles.
Clustering with a Spliced GPD Tail and Covariate-Dependent Weights
What you’ll learn
How to fit tail-aware clustering with dpmgpd.cluster().
How the type = "weights" dependence mode uses covariates to change cluster prevalence (mixture weights), while keeping component likelihood structure shared.
How to use predict() to obtain labels and a posterior similarity matrix (PSM), and how to interpret the label/PSM plots.
Purpose (in one sentence)
Fit a tail-aware clustering model where covariates affect cluster prevalence through mixture weights (type = "weights"), and the component likelihood is a spliced bulk + GPD tail model.
$K_star
[1] 5
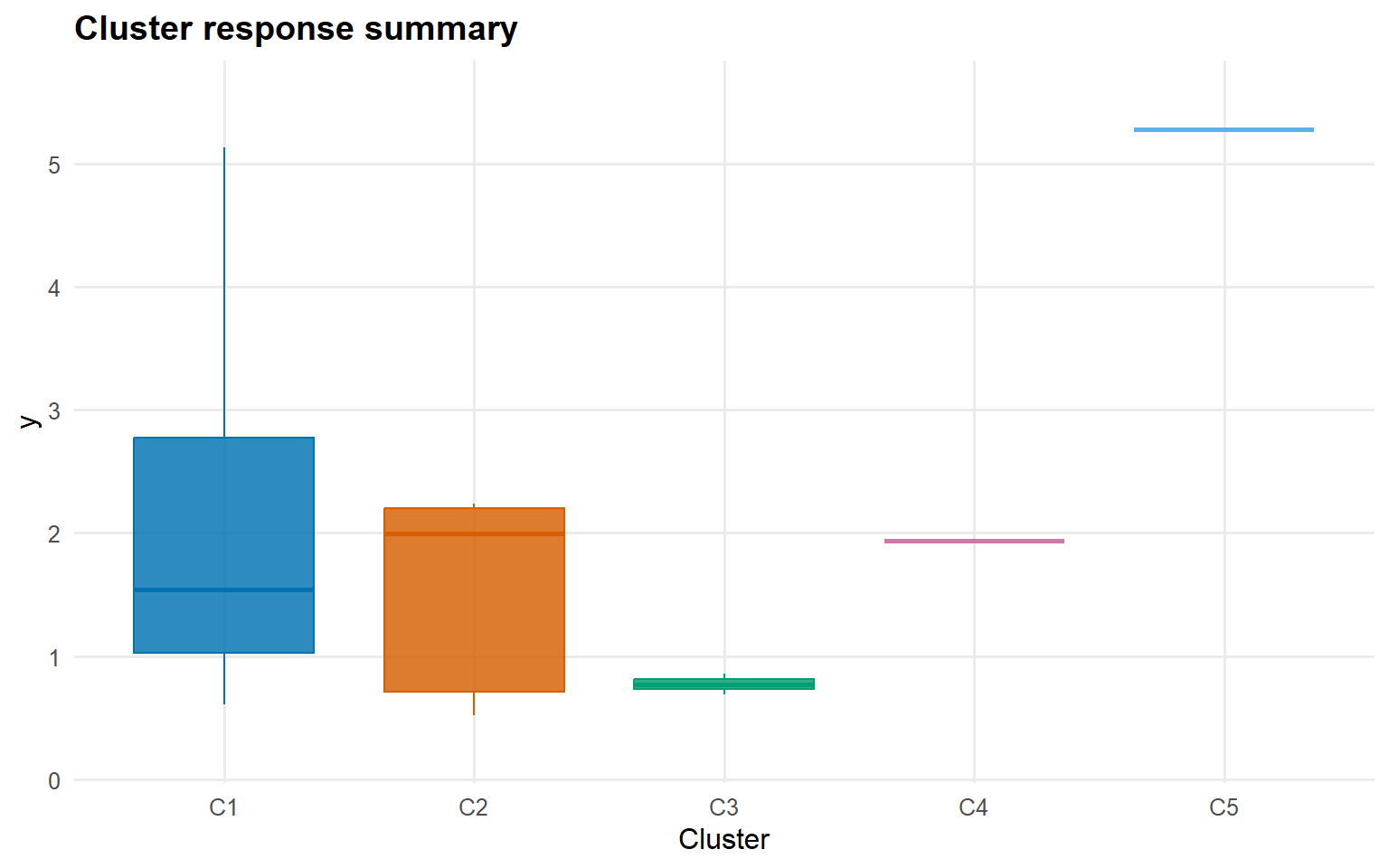
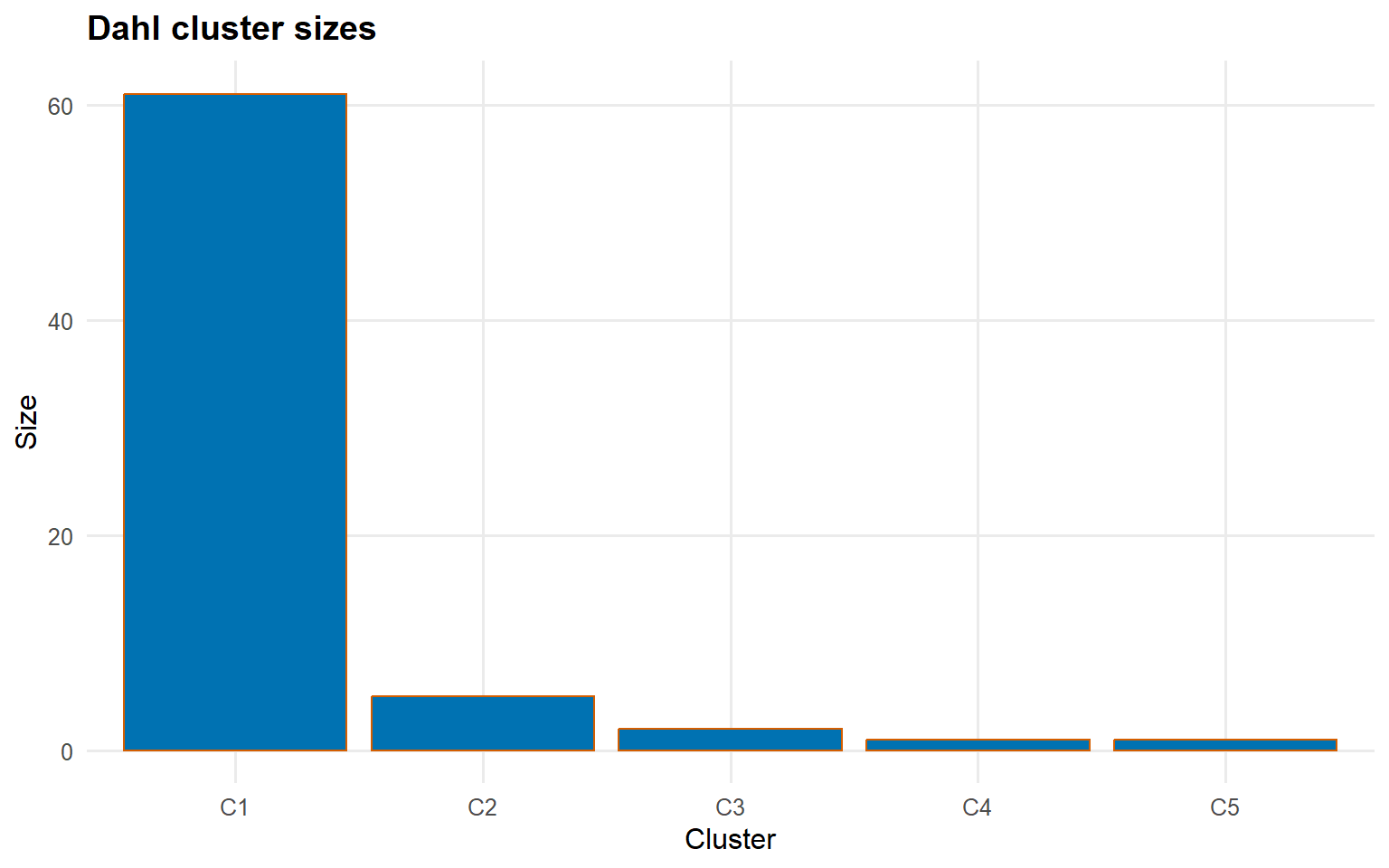
$cluster_sizes
1 2 3 4 5
61 5 2 1 1
$cluster_profiles
cluster n y_mean y_sd x1_mean x1_sd x2_mean x2_sd
1 C1 61 1.9519186 1.1309051 -0.008098264 0.9277559 0.04763821 0.5634605
2 C2 5 1.5332865 0.8451246 0.465058447 0.8558037 0.17916220 0.3363054
3 C3 2 0.7717176 0.1199999 -0.395431116 1.1312839 -0.55624407 0.2742523
4 C4 1 1.9395389 NA 1.241187447 NA -0.04143591 NA
5 C5 1 5.2783434 NA 1.079272215 NA -0.28493860 NA
x3_mean x3_sd certainty_mean certainty_sd
1 -0.0217340 0.9401597 0.3124220 0.03614309
2 -0.3689271 1.0437381 0.2656916 0.02948265
3 0.9168566 0.5688655 0.3065634 0.01406759
4 1.2865362 NA 0.3995354 NA
5 -0.8084690 NA 0.4036634 NA
$certainty
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.2209 0.2919 0.3205 0.3115 0.3383 0.4037
$source
[1] "train"
$burnin
[1] 0
$thin
[1] 1
attr(,"class")
[1] "summary.dpmixgpd_cluster_fit" "list"
This clustering configuration uses the formula/data-frame interface directly. Because type = "weights", covariates enter the gating model for cluster membership, while the spliced bulk-tail likelihood captures upper-tail differences inside each component.
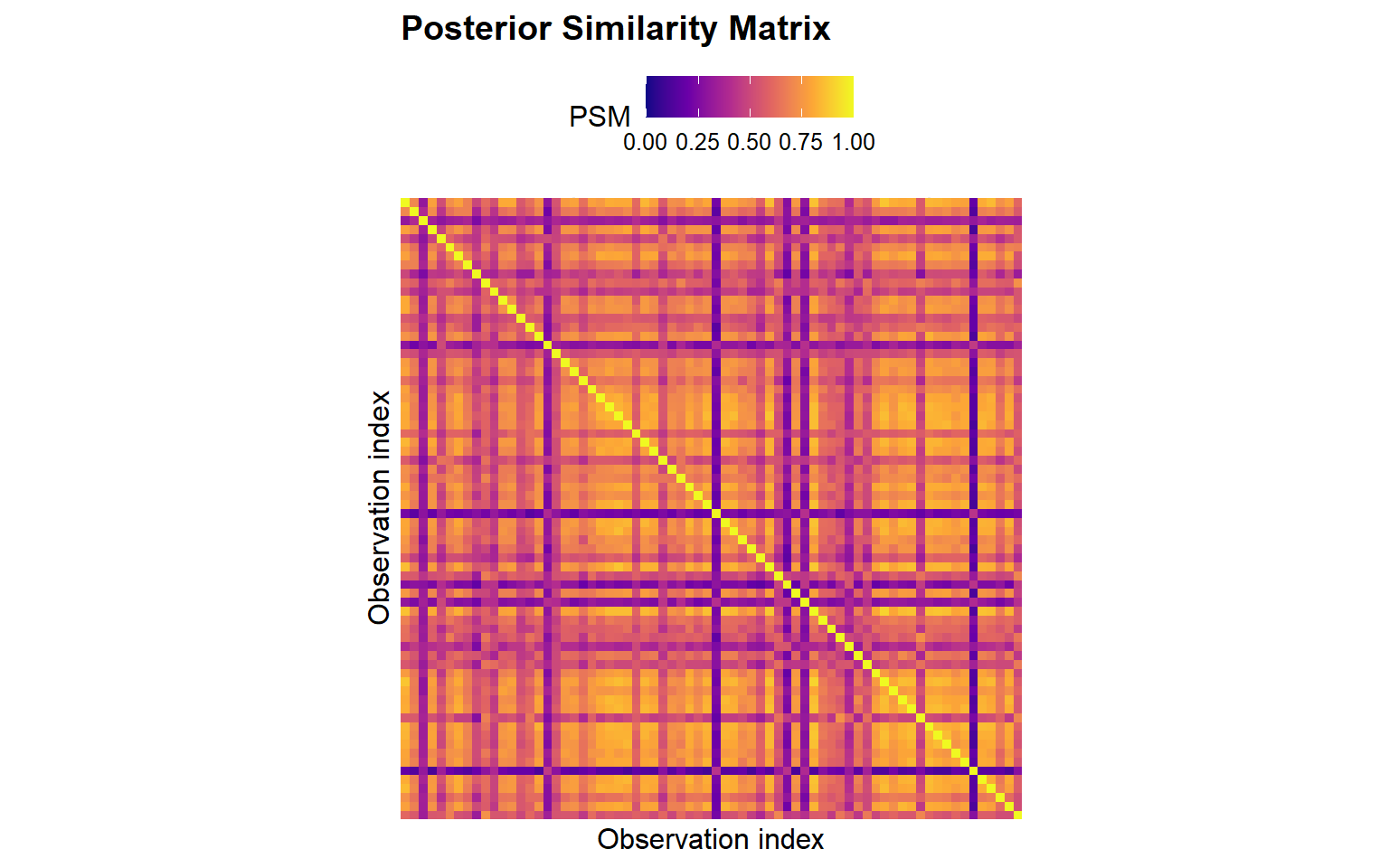
Training Labels and Posterior Similarity Matrix
Code
cluster_psm_gpd <-predict(fit_cluster_gpd, type ="psm")cluster_train_gpd <-predict(fit_cluster_gpd, type ="label", return_scores =TRUE)train_summary_gpd <-summary( cluster_train_gpd,vars =c("y", "x1", "x2", "x3"),top_n =5)train_sizes_tbl <-tibble(cluster =paste0("C", names(train_summary_gpd$cluster_sizes)),n =as.integer(train_summary_gpd$cluster_sizes))train_sizes_tbl
plot(cluster_train_gpd, type ="summary", top_n =5)
The PSM summarizes posterior co-clustering probabilities on the training sample, while the training label object gives the Dahl representative partition together with assignment scores and cluster-level summaries.
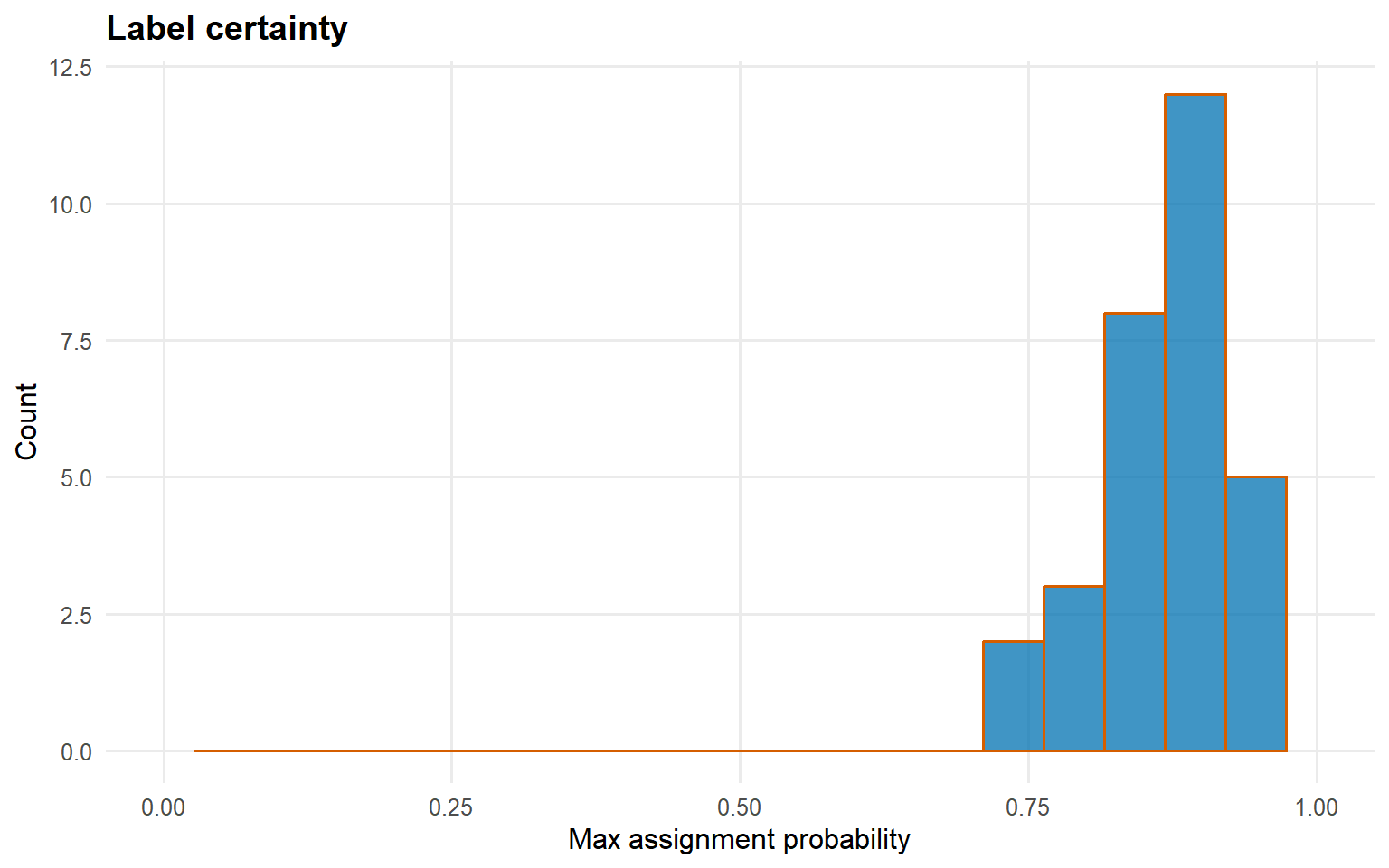
predict(..., newdata = ..., type = "label") maps held-out observations into the space of the representative training clusters. The returned score matrix can be summarized either numerically or with the built-in certainty plot above.
Takeaways
dpmgpd.cluster() is the current wrapper for tail-aware clustering.
type = "weights" is appropriate when covariates should change cluster prevalence rather than cluster-specific kernel parameters.
The standard post-fit workflow is predict(..., type = "psm"), predict(..., type = "label"), then summary()/plot() on the returned cluster objects.
The next page contrasts this with a bulk-only clustering model where covariates enter through parameter links instead of weights.