Website workflow note. This page reflects the current exported API and recommended wrapper-first usage. Last updated: 2026-02-19.
For the full package narrative, see the main package vignettes (basic, unconditional, conditional, and causal).
Unconditional CausalMixGPD: CRP Backend with Tail Augmentation
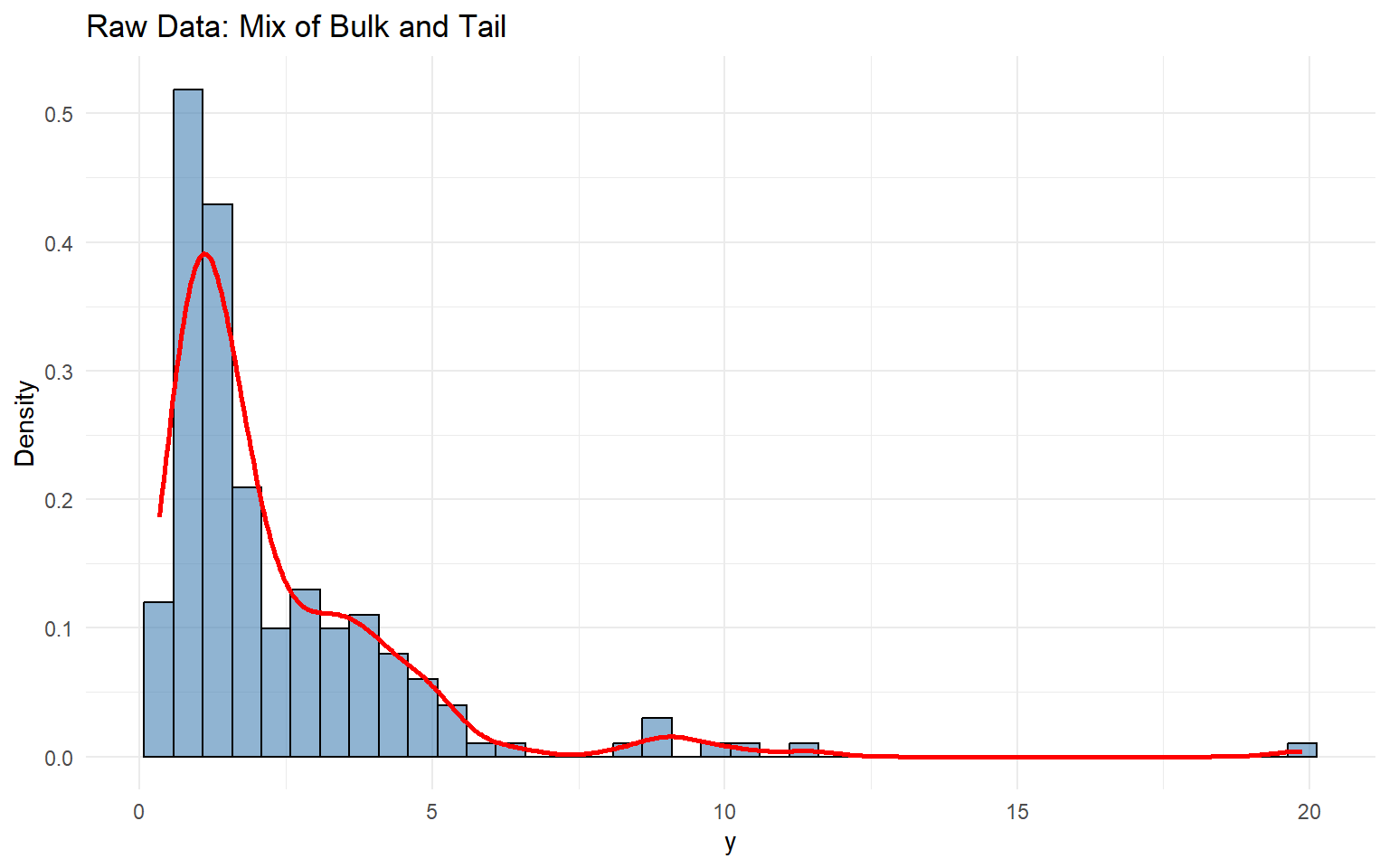
Purpose: Model the bulk of the distribution with a DP mixture (the “kernel” or bulk family) and let a GPD tail capture extreme values beyond a threshold. The CRP backend handles partitioning and we toggle GPD = TRUE to augment the tail.
What you’ll learn
How a bulk DP mixture + GPD tail splits modeling responsibility across typical and extreme values.
How to encode threshold behavior via param_specs and then evaluate tail summaries via predict().
How to read tail-aware predictions: density, survival, and high quantiles.
When to use this template
You have a single outcome with a visible right tail and need explicit extreme-tail modeling.
You care about tail risk summaries (survival probabilities, high quantiles), not only mean/density.
Next steps
Compare against the SB+GPD analogue (ex04) to see how truncation and partition behavior affect uncertainty.
Data Setup
Code
# Load data with an obvious taildata("nc_pos_tail200_k4")y_tail <- nc_pos_tail200_k4$yy_tail <- y_tail[is.finite(y_tail) & y_tail >0]# Summaries and tablesummary_tbl <-tibble(statistic =c("N", "Mean", "SD", "Min", "Max"),value =c(length(y_tail), mean(y_tail), sd(y_tail), min(y_tail), max(y_tail)))df_data <-data.frame(y = y_tail)ggplot(df_data, aes(x = y)) +geom_histogram(aes(y =after_stat(density)), bins =40, fill ="steelblue", color ="black", alpha =0.6) +geom_density(color ="red", linewidth =1) +labs(title ="Raw Data: Mix of Bulk and Tail", x ="y", y ="Density") +theme_minimal()
Code
summary_tbl
# A tibble: 5 × 2
statistic value
<chr> <dbl>
1 N 200
2 Mean 2.33
3 SD 2.30
4 Min 0.328
5 Max 19.9
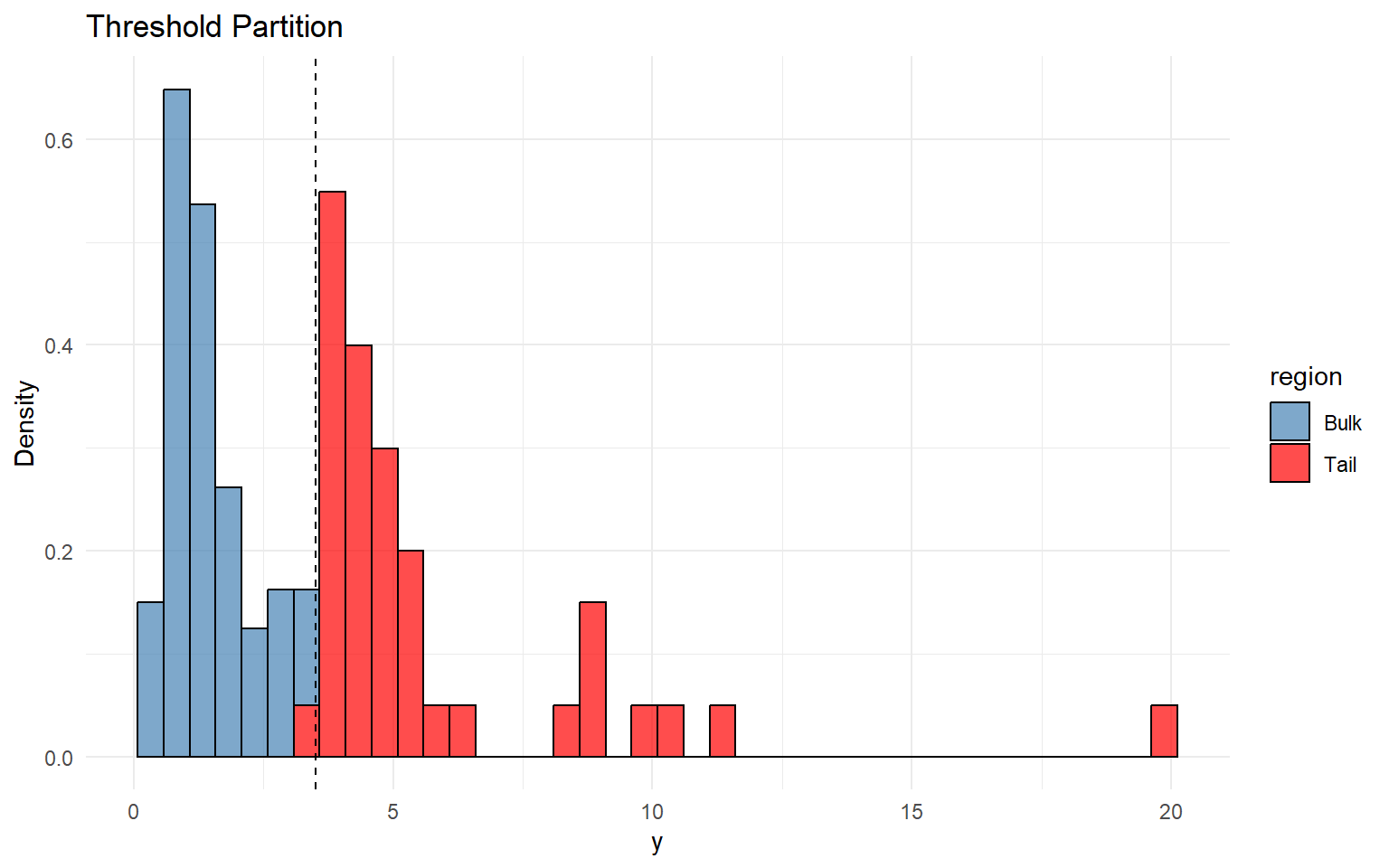
Threshold & Tail Partition
Code
thresholds <-quantile(y_tail, c(0.70, 0.75, 0.80, 0.85, 0.90))u_threshold <- thresholds["80%"]df_tail <-tibble(y = y_tail,region =ifelse(y_tail > u_threshold, "Tail", "Bulk"))ggplot(df_tail, aes(x = y, fill = region)) +geom_histogram(aes(y =after_stat(density)), bins =40, alpha =0.7, color ="black") +geom_vline(xintercept = u_threshold, linetype ="dashed", color ="black") +scale_fill_manual(values =c("Bulk"="steelblue", "Tail"="red")) +labs(title ="Threshold Partition", x ="y", y ="Density") +theme_minimal()
Model Specification & Bundle
This mirrors the direct bundle() workflow in start/backends-and-workflow, but with tail augmentation turned on (GPD = TRUE). Here we use an Inverse Gaussian bulk kernel and estimate the GPD threshold with a lognormal prior centered at the empirical 80th percentile.
# S3 plot methods highlight trace + density diagnosticsplot(fit_gpd, family =c("traceplot", "density", "running"))
=== traceplot ===
=== density ===
=== running ===
Code
plot(fit_gpd, params ="alpha", family =c("traceplot", "autocorrelation", "geweke"))
=== traceplot ===
=== autocorrelation ===
=== geweke ===
Posterior Predictions: Bulk and Tail
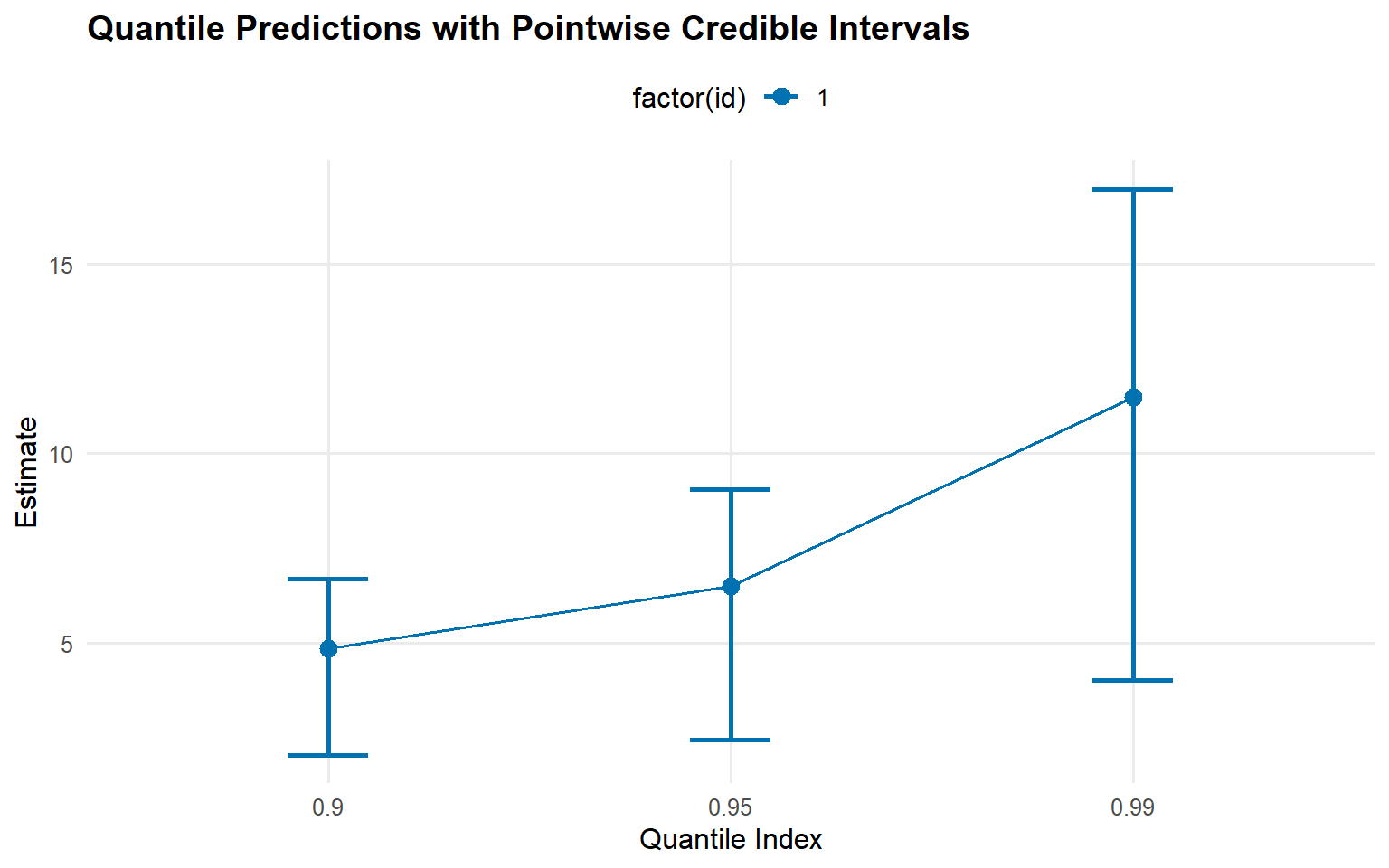
We use the S3 predict() objects and their dedicated plot() methods to visualize densities, survival curves, and posterior-mean quantiles (i.e., averages of q(p | \(\\theta\)) over draws).
Code
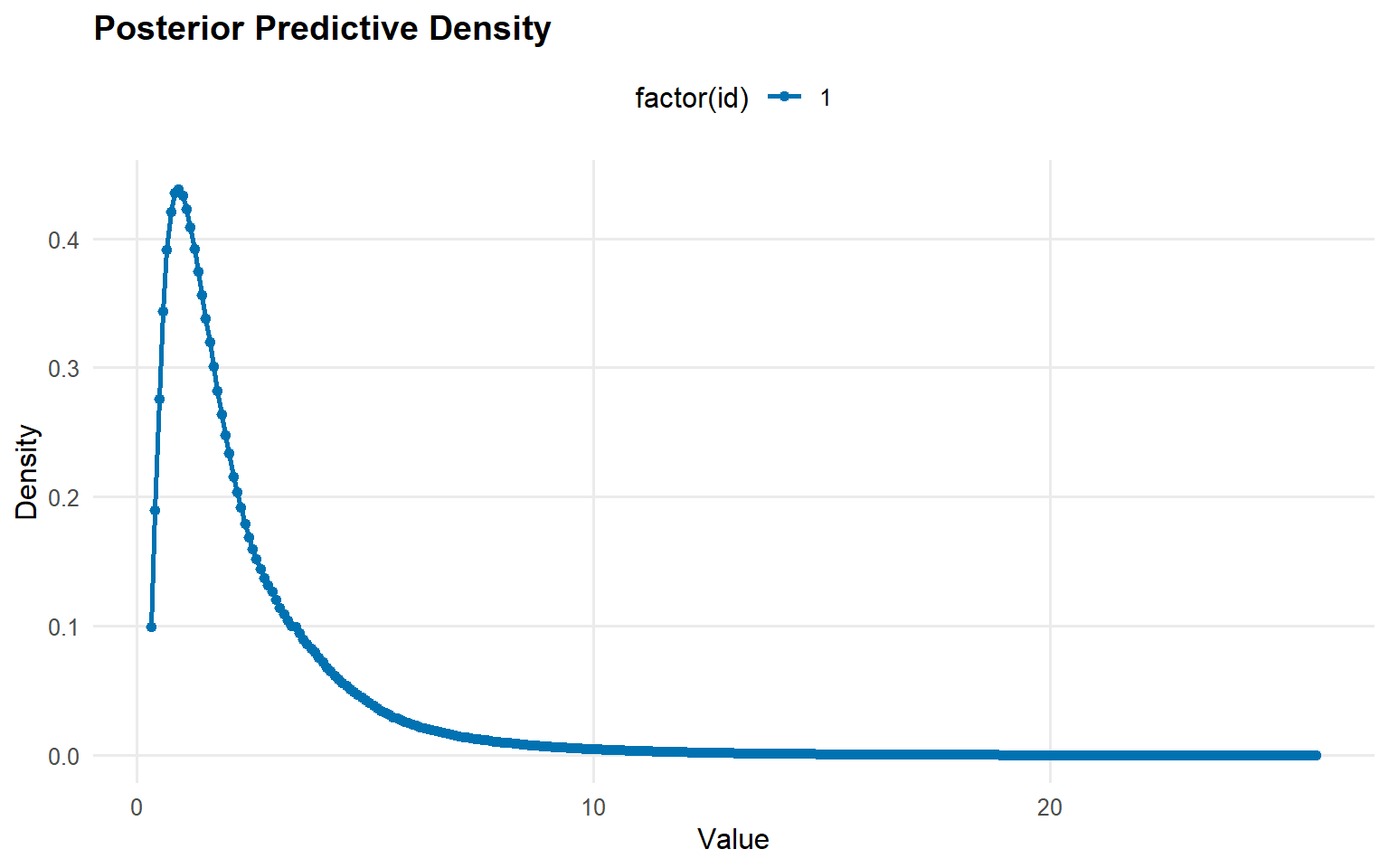
y_min <-max(min(y_tail), .Machine$double.eps)y_grid <-seq(y_min, max(y_tail) *1.3, length.out =300)pred_density <-predict(fit_gpd, y = y_grid, type ="density")plot(pred_density)
Code
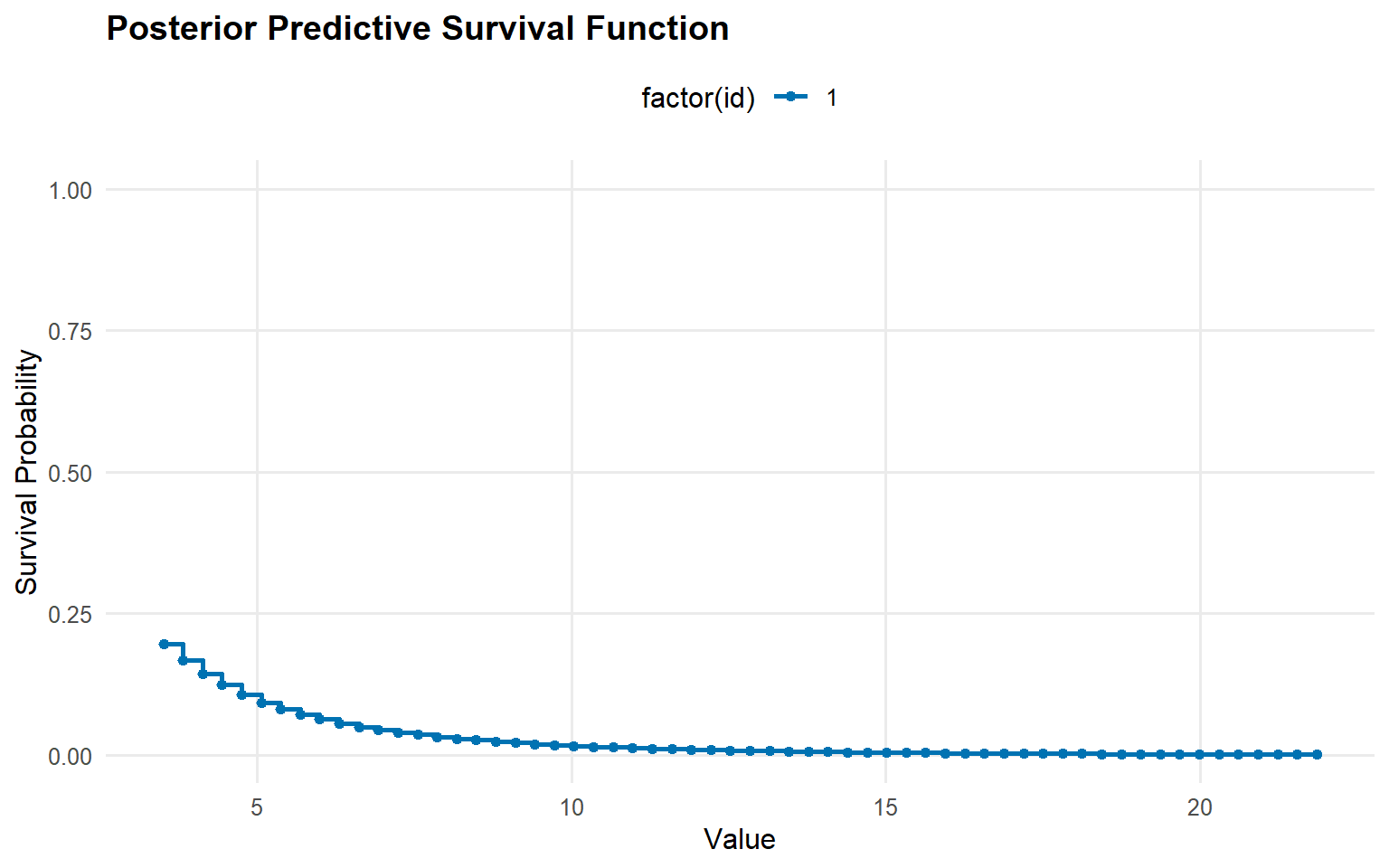
y_surv <-seq(max(u_threshold, y_min), max(y_tail) *1.1, length.out =60)pred_surv <-predict(fit_gpd, y = y_surv, type ="survival")plot(pred_surv)
Code
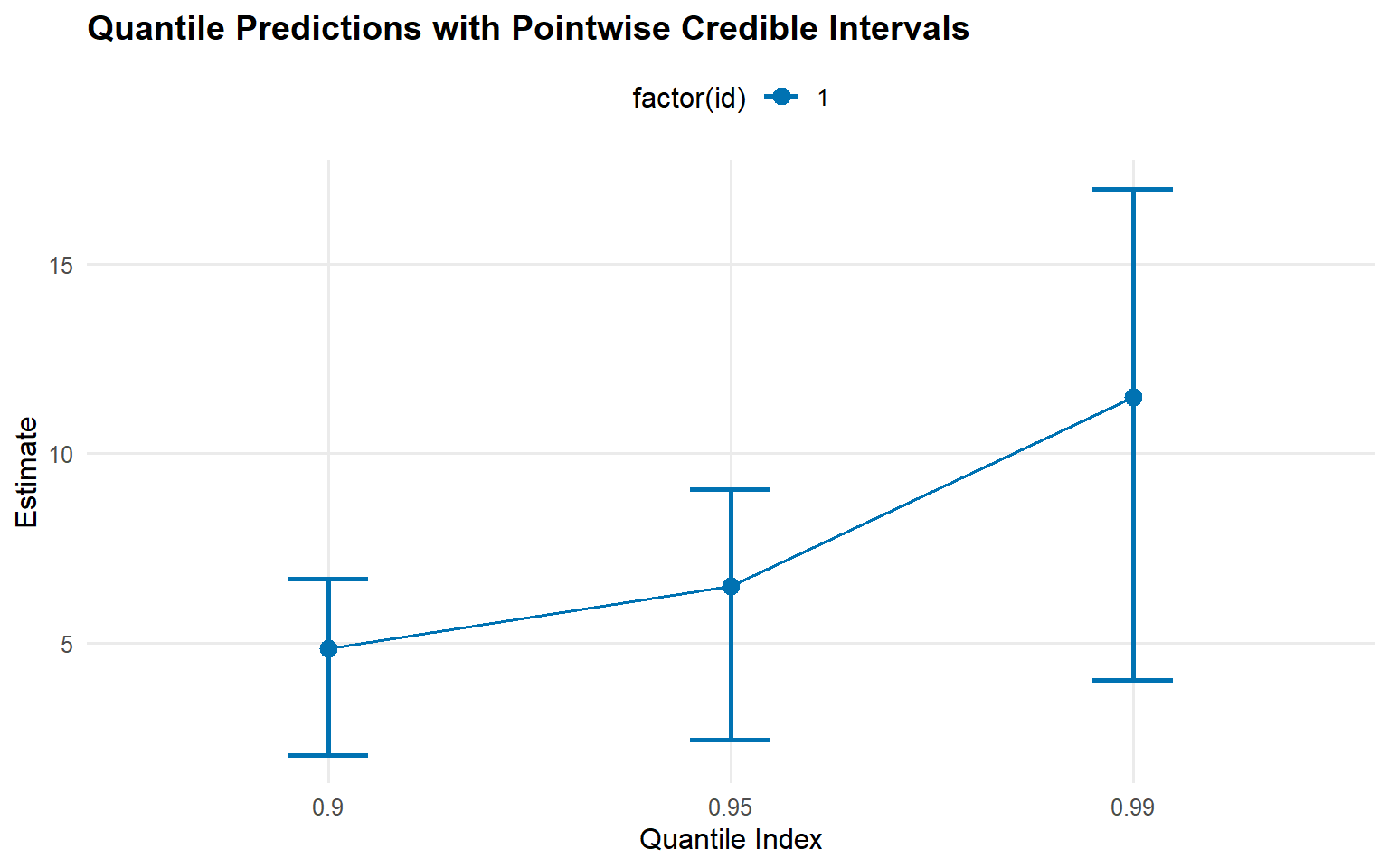
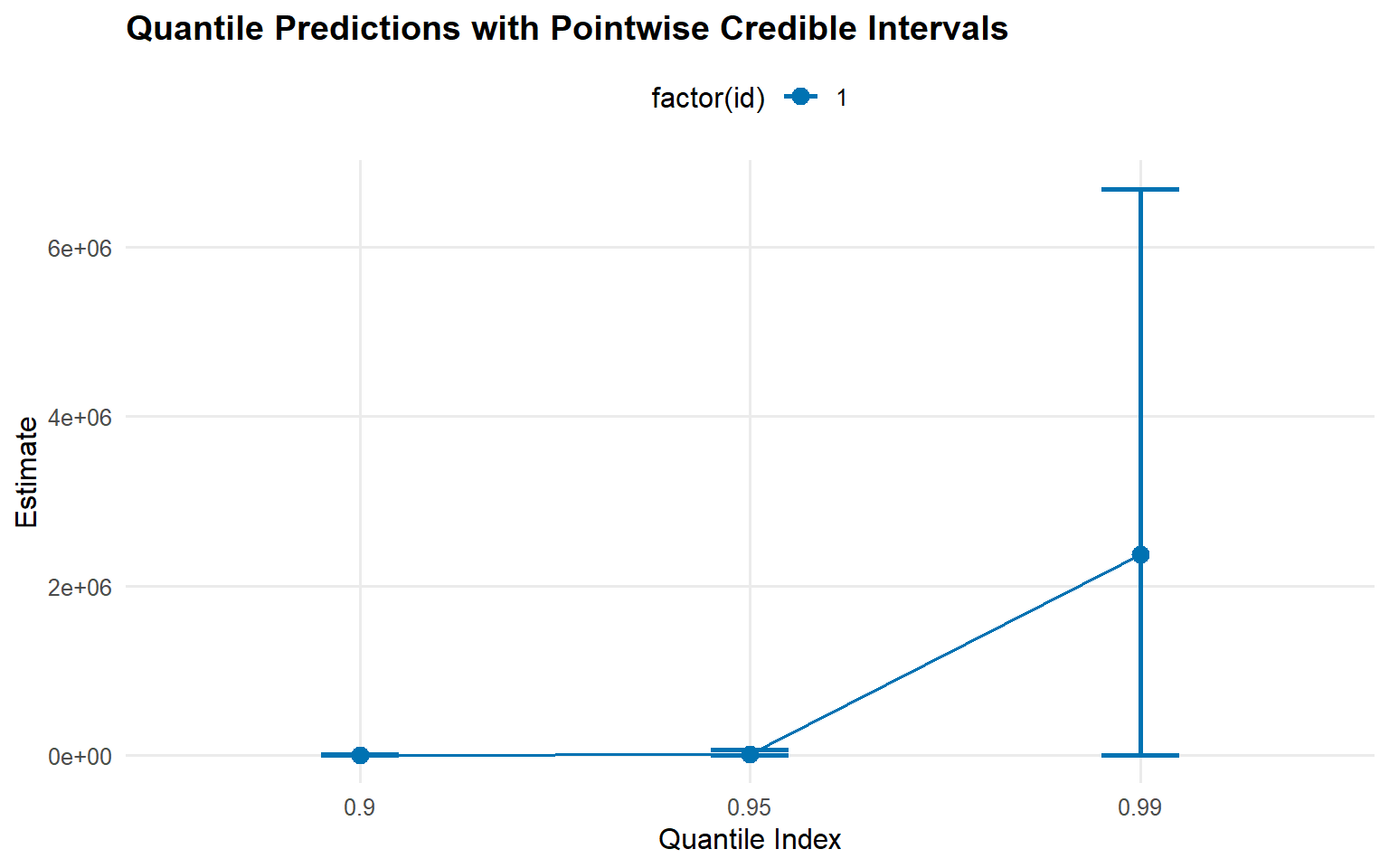
quantile_probs <-c(0.90, 0.95, 0.99)pred_quantiles <-predict(fit_gpd, type ="quantile", p = quantile_probs, interval ="credible")plot(pred_quantiles)
Bulk-Only Baseline Comparison
To demonstrate the value of tail augmentation, we fit a bulk-only lognormal DP mixture and compare posterior summaries against the InvGauss+GPD fit.